
How do Generative AI models actually think? Have you wondered recently (like I have) what happens between asking ChatGPT a question and getting an answer?
It’s not an impossible question to answer but “it’s complicated” is also a valid response. Large Language Models are built by using computer programs to read tons and tons of sentences. This process generates statistical weights or probabilities that tell a future computer program (like ChatGPT) how likely any particular word Y is to follow any particular word X.
This is obviously a deeply unsatisfying answer.
Anthropic open-sourced some interesting circuit tracing tools last week, giving us X-ray vision into AI’s thought process.
Why This Matters
Trust Problem: When AI gives you an answer, how do you know it’s right without manually rechecking it.
Debugging: When AI does return hallucinated or misguided answers in your business logic… where did it go wrong?
How to Use Circuit Tracer
We don’t need any code to get started today… There’s a handy web interface that visually implements this technology at Neuronpedia here: https://www.neuronpedia.org/gemma-2-2b/graph.
Getting Started
- Go to the Neuronpedia circuit tracing interface
- Let’s start with reviewing the default phrase that is supplied “the capital of the state containing dallas is”.
Side note… this is an excellent example input because “capital” has a lot of meanings in English and also this example requires a logical hop where the model has to conceptually arrive at Texas first, then jump off to Austin - All the input words are shown across the bottom X-Axis. Click on “capital” for this example.
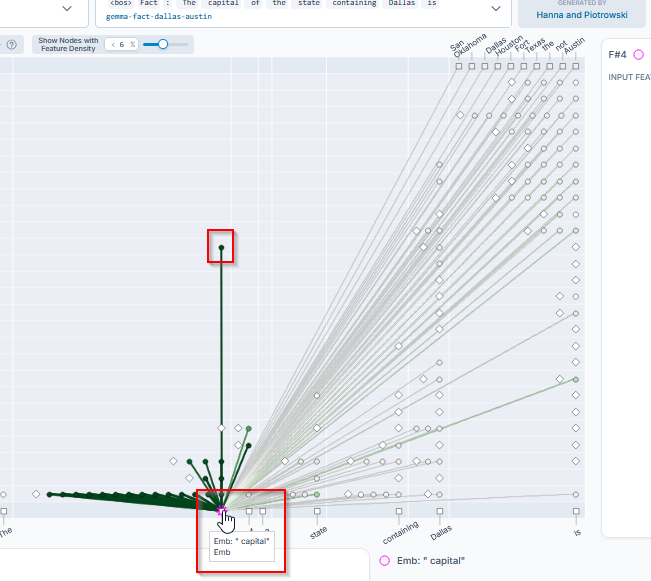
Understanding What You See
The Main Graph (Top Left) This shows the AI’s reasoning as a network. Your prompt appears as tokens along the bottom. The AI’s possible answers appear at the top right. The nodes in between are “features” – concepts the AI uses internally.
When you click a node, it highlights in pink and shows all its connections. Think of it like a mind map of how the AI connects ideas.
The Connected Nodes Panel (Top Right)
Once you have a feature node selected… this shows what it connects to, sorted by importance. Since we highlighted capital in the previous step… look at how the model is beginning to converge on the appropriate meaning of “capital” in this sentence. The outputs here are weighted by their likelihood with capital cities being the highest weighted output in this context.
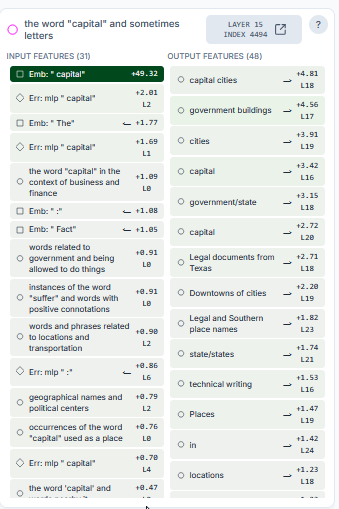
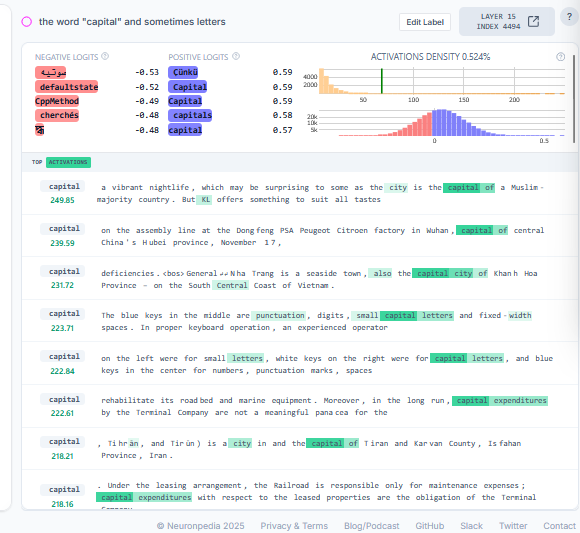
Feature Details (Bottom Right)
- Top activations: Real text examples of where this was found in the training material specifically.
- Logits: What words this feature pushes the AI to say
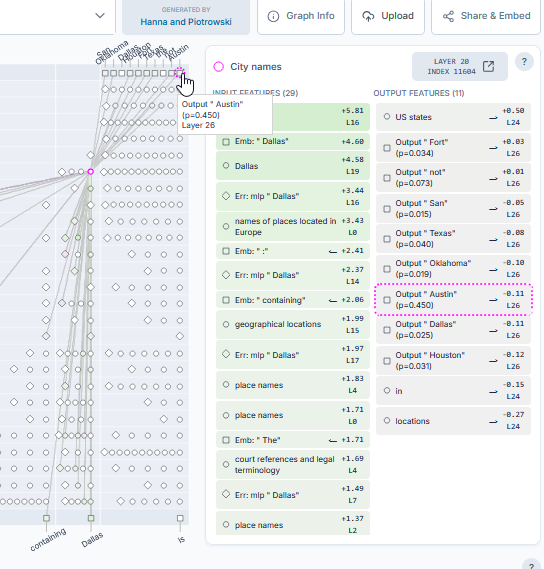
Arriving at an answer
OK… We’re closer but still not at our final answer. Let’s move along another few hops in the reasoning chain. We’re going to select one of the Dallas features now. We can see that the output options with their statistical probabilities. In this case the next token is 45% likely to be Austin. This is great since it has a high probability and it’s also much higher than the next most likely answer which is “Texas” at 4%…
The Limitations
Circuit tracing isn’t magic:
- This process currently works on relatively small models (Gemma-2-2b, Llama-3.2-1b)
- Complex reasoning creates complex graphs that take research to untangle and understand
- With this process we’re able to see a part of the picture, not everything going on inside a model
Try It Yourself
The barrier to entry is zero. No coding required, no installation needed. Just visit Neuronpedia and start exploring how AI actually thinks.
Also check out the full work cited on the Github repository here https://github.com/safety-research/circuit-tracer.
This circuit tracer is based on work by https://transformer-circuits.pub/2025/attribution-graphs/methods.html and https://transformer-circuits.pub/2025/attribution-graphs/biology.html
Start exploring at Neuronpedia’s circuit tracing interface. Share interesting findings !
